get in touch
04
OUR SOLUTIONS
DATA INTEGRATION FRAMEWORK
Shorten your time to market and cut the cost of any data warehouse or data integration project using the Framework that applies design & development standards, reusable modules and software components.

Data Integration Framework enables you to have design & development standards at your disposal. Using reusable modules and software components ensures high quality and faster time-to-market for any data warehouse or data integration project by leveraging industry leading ETL/ELT tools and data storage platforms.
Key Benefits
Standardization
Using NEOS DI Framework negates non-existing development and documentation standards through the use of documentation and development standards.
Efficiency and Reusability
Eliminates inconsistent approach to common tasks and single usage of developed components through ETL process templates and generic modules, as well as industry specific data models & reusable algorithms. Tightly integrated with different ETL Tools (OWB, ODI, Informatica, etc.).
Best Practices
Removes high implementation cost and risk by using proven principles and modules and based. The Framework is based on hands-on experience and tested on a number of projects.
Easy Maintenance
By completely eliminating the need for different consoles, logs and monitoring tools, the framework enables easy monitoring and administration through a single console.
Components
NEOS DI Framework is a set of different components ranging from different types as standards and architecture recommendations, predefined modules & templates to support integration with specific ETL/ELT tools, SW components supporting advanced scheduling and agents performing all kinds of running and maintenance tasks.
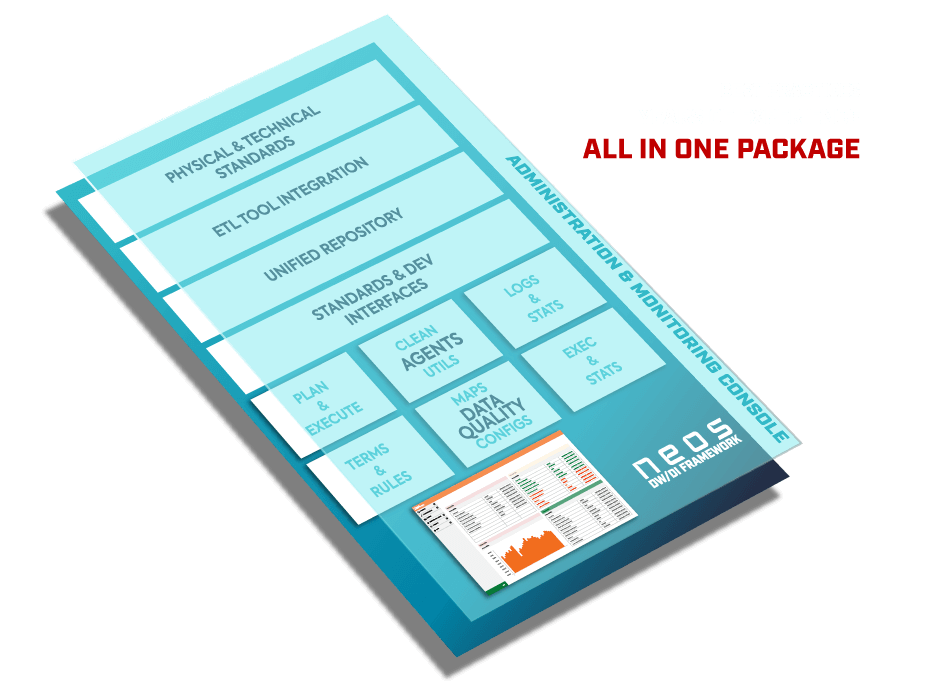
MODULES
- Architecture
- - Logical stages & modelling principles
- - Physical architecture landscape & guidelines
- Data Modeling
- - Industry Specific Data Models & Patterns
- - Naming Conventions
- - Physical Parameters (Tables, Tablespaces, Sequences, etc.)
- - Standards for partitioning, compression
- - Database Configuration Parameters
- ETL/ELT
- - Best Practice Reusable Algorithms
- - Standardized ETL Module Parameters
- - ETL/ELT Tool specific components & configurations
- Purpose
- - Standardize ETL/ELT development
- - Increase development efficiency
- - Ensure team members intra-projects switching
- - Avoid inconsistent approaches and enable ETL/ELT developers to focus on business defined transformations rather than system tasks
- ETL/ELT Tool-specific objects
- - Predefined ETL/ELT process/module templates for each stage (staging, enterprise model, data mart, etc.)
- - Common pre/post process and mapping components interacting with framework repository
- - Reusable, pre-defined modules for the standardization of complex tasks (scd2, complex calculation, etc.)
- Purpose
- - Schedule each ETL/ELT process execution period, including data loading window definition
- - All defined context parameters are automatically available as parameters to use in ETL module for data extraction and filtering/identifying dataset to be processed
- Schedule Definition
- - Process (created in ETL/ELT tool)
- - Process schedule template
- - Source (if the same process is used for multiple sources)
- - Calendar (if different calendars are used for different sources or schedules)
- Schedule Context
- - Execution Period (sec, min, hour, day, workday, week, month, quarter, year)
- - Offsets (definition of how data extraction parameters should be calculated)
- - Dataset extract date calculation (can be calculated based on schedule date, period from, period to, current timestamp, etc.)
- Simulation
- - Can easily simulate how execution period will look like based on defined schedule
- Purpose
- - Extracting all available ETL/ELT metadata defined in a specific tool
- - API interfaces for other framework module required functionalities (starting process and similar)
- - Standard templates/components for each supported ETL/ELT tool
- - Utilities for automatization of specific development, deployment and other tasks
- ETL/ELT Tool-specific objects
- - Repository data extraction logic interfaces
- - API interfaces
- - Process/mapping templates and pre/post modules
- - Development and deployment automatization utilities/scripts
- Supported ETL/ELT Tools
- - Oracle Data Integrator
- - Oracle Warehouse Builder
- - Informatica PowerCenter
- Purpose
- - Provides storage for all data integration metadata related entities
- - Enables additional parameterization including using legacy DI code
- - Defines a common metadata model for ETL/ELT repository tools interfaces
- Areas
- - Environment (Environments, Repositories, Contexts, etc.)
- - ETL Objects (Process, Module, Steps)
- - Data Models (Models, Stores, Areas, Relationships, etc.)
- - Scheduler (Schedules, Calendars, Sources, etc.)
- - Execution Context (Process Sessions, ETL Sessions, Logs, etc.)
- - Parameterization (Process, Agents, System parameters, Locations, etc.)
- Objects
- - Core repository metadata tables
- - Specific ETL/ELT tool repository interface access views (VR)
- - Common unified metamodel views (VC)
- - Integration views combining VC views for easier usage (VI)
- In order to further enhance developer experience in using ODI and minimize additional tasks that require execution while the development of data flow is being finished(mappings, packages, etc.), as well as to remove any possibility of user error while adding new features or enhancing existing ones, NeoOdiDeploy tool was created with following in mind:
- 1. Fully automate export / import process of ODI components from one environment to another (including creating backup copies, validation, rollback in case of inconsistencies etc).
- 2. Remove all extra steps from developer:
- a) You don’t need access to all environments in your DW pool
- b) Don’t worry about objects validation, whether they are old or new
- c) Don’t worry about versioning
- d) Don’t worry about dependencies
- Monitor
- - Currently Running/Error/Late processes
- - Why certain process haven't started
- - What is the overall error cause
- strong>Administration
- - Process Parameterization & Scheduling
- - Manual start/stop execution
- - Configuration Parameters (Agents, Processes)
- Operator
- - Monitor critical processes
- - Notify responsible group of persons on specific events (errors, warnings, start/end of specific process, etc.)
- - Start/Stop processes
- Statistics
- - Execution times/trends
- - Activity types time consumption
- - Top N analysis
- Maintenance
- - Automatic Cleaning of Processed Data (based on ETL execution status)
- - Intelligent – Technology specific Execution (fe. drop partition vs delete sensitive)
- - Automatic and ETL aware Statistics Calculation
- - Automatic Tablespace cleaning and other DBA tasks
- - Configurable on the Lowest Level
- strong>Log & Stats
- - Additional Process Execution Statistics
- - Detail logs of execution times, type of operations
- - Base for Performance Issues Analysis
- Plan & Execute (RWYC)
- - RWYC Principle Based Execution
- - Dynamic Execution Plans
- - Based on Prerequisites Automatically Identified from ETL Repository
- - Configurable (Priorities, Execution Times, etc.)
- - Easily Integrated with existing schedulers (Tibco, DB, In-house, etc.)
REFERENCE ARCHITECTURE
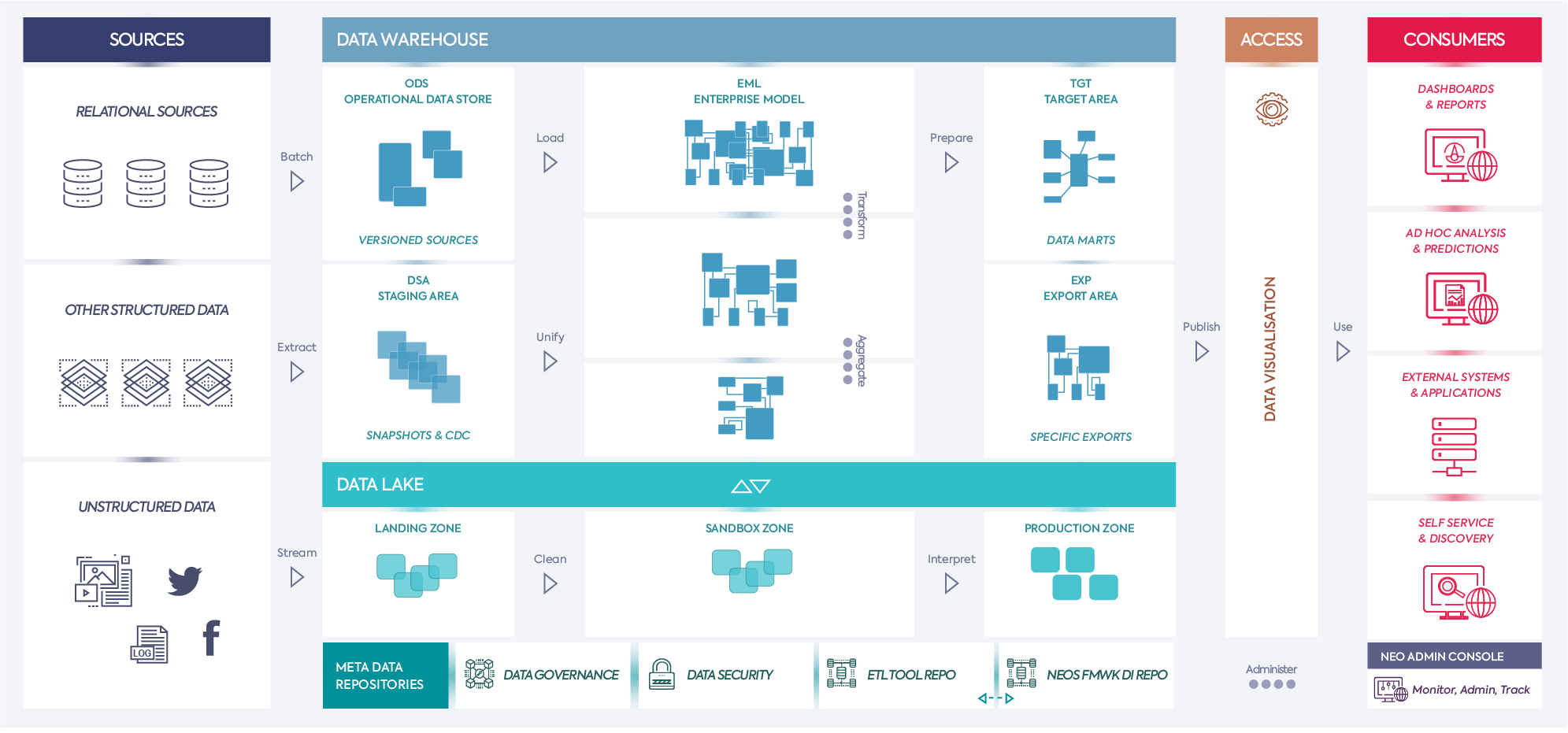
The reference logical architecture for Neos DI Framework is based on a number of implemented projects and best practice paradigms. This image represents a high-level overview of different areas and data flows that should be taken into consideration when designing an enterprise level data warehouse and analytics system.
| Area | Purpose | Nature | Data Tracking |
|---|---|---|---|
| Data Staging Area (DSA) | Storing source data deltas/snapshots to be processed further in DWH Reducing load on source systems Converting to common technical platform Used also as Landing Zone (part of Data Lake) |
Source data (no transformations) Temporary storage For specific sources can be also implemented as Operational Data Store (ODS) having same structure as source data but with history/versioning included |
Standardized ETL procedures Each dataset is marked with Identifier (SSN_ID) as a reference to metadata details about source, extraction type and period and number of other information automatically loaded as part of Neos DI Framework |
| Operational Data Store (ODS) | Snapshot of current data in specific data source with latest data Can be also used to store limited number of snapshots of source data Used as intermediate stage between transactional databases and DWH (EML) and/or for operational reporting purposes |
Usually data model is same/similar as one on source systems with optional extensions to store versioned data | Standardized ETL procedures Each dataset is marked with Identifier (SSN_ID) as a reference to metadata details about source, extraction type and period and number of other information automatically loaded as part of Neos DI Framework |
| Enterprise Model (EML) | Industry specific common model Unified & Cleansed data definitions Logical model – Business oriented Source systems independent |
Semi-Normalized Model Storing lowest level of granularity Minimizing storage requirements Data model is based on business entities and relationships Data structure should not be affected by source system changes in most cases (except in cases additional data is introduced) |
Change Tracking (SCD2, ETL Sessions info) There are more stages ranging from storing data on lowest level of granularity to transformed unified data based on common definitions and calculations |
| Target Model (TGT) | Common stage for accessing data thru reports, dashboard and ad-Hoc analysis Also, can be based on specific external consumers requirements on structure and calculations (like central bank etc) Accessed by End Users and/or external systems |
Star schema like models Specific Data Marts Shared dimensions/objects Specific export formats defined by external institutions/systems |
Loaded from EM Version Tracking Context Specific Easily Restorable and reloadable based on requirements Unified view across different datamarts |
| Data Lake (DLE) | Storing large amounts of RAW data for discovery and further processing Streaming / near real-time data pipelines Staging area and Operational Data store Data archiving Complex processing involving large data sets and intensive CPU usage (simulations, data mining and similar) |
Unstructured or semi-structured datasets depending on different stages: Landing Zone: data in native format loaded as quickly and as efficiently as possible without any transformations at this stage Sandbox Zone: Partially and subject oriented interpreted, structured and cleansed data for specific domain of exploration Production Zone: Curated and described data sets with well-defined structure and purpose as a result of cleansing and transformations based on business logic. |
Each dataset is marked with Identifier (SSN_ID) as a reference to metadata details about source, extraction type and period and number of other information automatically loaded as part of Neos DI Framework |
| Framework Repository (NEO) | ETL/ELT orchestration including process metadata & execution traceability/lineage Advanced Scheduling & parametrization Prerequisites & Dependencies Ensuring Data Load Traceability & Consistency |
Common metadata repository tables and views/APIs for automatic integration of data from specific ETL tool repositories Common ETL/ELT Templates & Modules ETL/ELT Tool Repository Access Layer |
All datasets are tracked by specific IDs with reference to metadata automatically loaded based on development/deployment of new objects and/or process execution results Log tables with all details on each specific change and execution More details can be found in materials related to Neos DI Framework |