
get in touch

The latest ASR model for NLP was trained on 300 hours of Croatian Parliament data – But how good it is for audio extraction and automated transcription? We have the answers.
Introduction
Automatic Speech Recognition (ASR) represents the process of transcribing speech into text. It is a popular computational linguistic use case that combines machine learning, audio signal processing, and natural language processing.
The history of ASR started in 1952 with a program called Audrey by Bell Labs. For reference’s sake, this was 7 years before Arthur Samuel coined the term Machine Learning. Audrey could only transcribe simple numbers, but it was a promising start, nevertheless.
Machine learning took over in the late 1970s with the usage of Hidden Markov Models and Trigram Models and in the late 1980s with the breakthrough of Neural Networks. The application of machine learning in speech recognition is still booming with the advent of big data, cloud computing, and the ability to utilize GPU power. All of this contributed to the development of end-to-end deep learning ASR models such as the one that we used.
In this article, we demonstrate the use of the Croatian language ASR model in transcribing Croatia’s Gov’t session. Why? We wanted to create a word cloud that consists of the most meaningful bigrams or single words from that transcription with help of NLP methods. The article will also demonstrate the creation and usage of closed captions from audio files.
The used model was downloaded from Huggingface and was fine-tuned with 300 hours of recordings and transcripts from the ASR Croatian parliament dataset ParlaSpeech-HR v1.0. Also, all audio recordings of Gov’t sessions are publicly available.
We used Python programming language and its modules to develop this solution. We’ll put the code, links to the used model, and audio on GitHub for ease of sharing. But, before jumping to the results, it’s a good idea to get a better grasp of the code itself.
Wav2Vec2-XLS-R-Parlaspeech-HR Explained – An NLP Model with a Full Croatian Support
The used model is available at the Huggingface CLASSLA site – short for CLARIN Knowledge Centre for South-Slavic Languages. CLARIN stands for Common Language Resources and Technology Infrastructure, Slovenia. It’s quite a mouthful, so don’t expect to get the acronym down in one reading.
CLASSLA contributes to the development of NLP for the Croatian language by creating datasets, models, and methods. Their researchers based the wav2vec2-xls-r-parlaspeech-hr model on Facebook’s wav2vec 2.0 version model called XLS-R which has over 300 million parameters. The name XLS-R comes from another Facebook’s state-of-the-art model called XLM-R where ‘XLM’ stands for Cross-lingual Language Model but with an ‘S’ for Speech. Letter ‘R’ in the end stands for RoBERTa – Google’s BERT model for contextual text encoding with a robustly optimized pretraining approach. Phew! That was a lot…
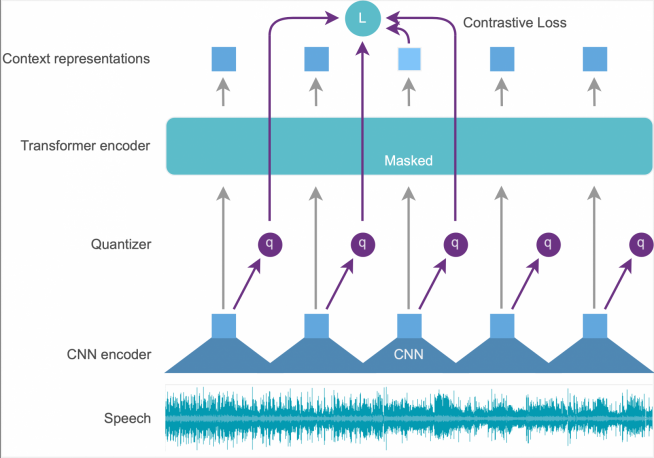
The wav2vec2-xls-r-parlaspeech-hr model first processes the raw waveform of the speech audio through a multilayer convolutional neural network to get latent audio representations of 25ms each. This is then quantized and sent to a contextual transformer encoder (RoBERTa) which then gives us context representations as result.
Figure 1 - The model
Also, this model is self-supervised which means that it can be fine-tuned on unannotated data to build better systems with certain language or domain preferences. Original Facebook’s model achieved the word error rate of 5.2% on the standard LibriSpeech benchmark when trained with just 10 minutes of transcribed speech and 53,000 hours of unlabeled speech.
Many languages are under-resourced or don’t have developed NLP support which is the perfect use case for this model. This was the case for the Croatian language until recently. The beginnings of the Croatian NLP started with HACHECK – Croatian Academic Spelling Checker. It was made in 1993 and was one of the first Croatian NLP projects that enabled computer verification and improvement of text quality.
As for the datasets, the first corpus for the Croatian language (Croatian National Corpus) was compiled in 1998. under a grant by the Ministry of Science and Technology of the Republic of Croatia and consisted of newspapers, magazines, books and sciences (74%), imaginative text like novels, stories or essays (23%), and other mixed texts (3%). All Croatian corpora at that time weren’t POS tagged and that was a hard disadvantage that stagnated the development of NLP support for an inflectionally rich language such as Croatian.
The first good POS tagger with an accuracy of 97% was eventually introduced in 2013. Croatian stemmer with a good precision of 98% was made in 2015, as a refinement of the first stemmer from 2007. Finally, CLASSLA modernized and standardized all this and more and made it easily accessible by creating the CLASSLA Python module available for installation through the PIP manager since July 2020.
Ultimately, using the CLASSLA module enabled us to extract more meaningful collocations or words when creating a summary in form of Word Cloud by utilizing the module’s tokenization, lemmatization, and POS tagging features. But first, we need to start with a transcription.
Why Do We Need to Transcribe Audio Files and How to do It
Transcribing large audio files in one piece such as the one we chose for this demonstration requires a tremendous amount of memory and computing resources. The reason is simple: at the final stage of transcription RoBERTa – the contextual transformer encoder – tries to find and preserve all the context gained from many input groupings and combinations.
Additionally, RoBERTa and all BERT family encoders have a maximum sentence length of 512 tokens. If a sentence exceeds that limit, RoBERTa breaks the sentence and possibly loses context from the last token of the first part and the first token of the second part. That is why we decided to first cut our raw input audio into chunks and then do the transcription for each. Finally, we merged chunk transcriptions and gained the resulting transcription for the used input.
Sequential cutting of the audio into relatively big chunks can drastically ruin the possibility of preserving the context, so we tried an alternative approach – silence detection. We implemented the function that cuts the audio exactly where the detected silence is longer than 200 ms and not louder than -50 dbFS. It gave us 234 chunks where 28 of them are less than 1 second long.
It made us wonder if short chunks could be filler words and other unidentified or nonspeech noises, so we listened to them all – and indeed they were. After getting rid of them we were left with 206 chunks where the mean duration of the chunk is 7.37 seconds and the longest one is slightly over a minute long.
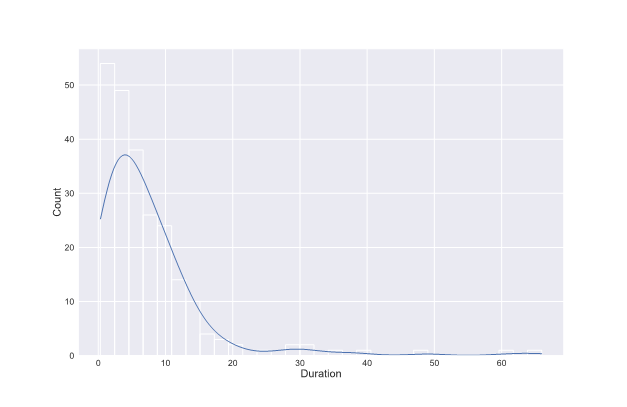
Figure 2 - Duration histogram
We tried one more thing with the audio before extracting knowledge from a transcription, and that is normalization. It represents a process of changing audio’s overall volume by a fixed amount to reach a target level. All created chunks of original audio were normalized to -3 dB and saved as a copy to amplify quiet parts of speech that happen naturally. These include the speaker’s remaining breath, thinking while speaking, technical issues, and sentiment expressiveness.
All that’s left to do is sequentially transcribe original and normalized chunks using CLASSLA’s model. Figure 3 shows three Word Error Rate metrics: HACHECK’s main word error rate which represents grammatical errors, HACHECK’s secondary word error rate which considers only stylistic errors, and nonexistent word rate. We can see that normalization didn’t improve the quality of transcription as metrics are lower for original audio chunks:
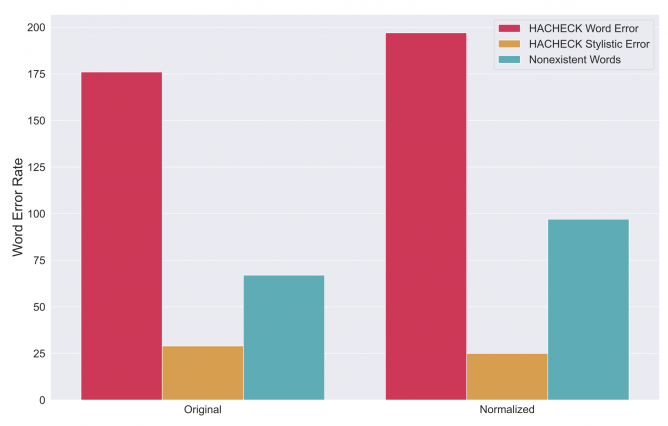
Figure 3 - Word error rate
Transcription for the first few chunks is shown in Figure 4. It shows obtained transcription as well as its correction which were done manually for demonstration purposes. We immediately conclude that model has some problems with understanding spoken numbers and with vowels that are often close in Croatian vocabulary such as “i” and “e”:

Figure 4 - The transcription
Now that we have the transcription, let’s jump into the good stuff – the first one being Word Cloud.
What are the Most Common Words Said in the Session?
The Croatian Gov’t Sessions are a perfect example of something that is not so short and can’t be listened to in a hurry to understand the summary (our chosen session is 00:29:15 long).
One of the options is to automatically summarize acquired transcription. Because automatic summarization methods usually depend on sentences, we were not able to do it that particular way due to the used ASR model’s nonpunctuated transcription output. Unfortunately, Croatian NLP does not yet support efficient and accurate subsequent punctuation of the text.
So, we went with the approach of finding the most common words or collocations to construct a word cloud. Generated transcription is tokenized, POS tagged and lemmatized using the CLASSLA Python package. Then, a vectorizer was used to transform the text into number representation which enables obtaining the frequencies for all the lemmas appearing in the transcription.
The top 20 most common and top 20 least common lemmas are shown in Figure 5. We can conclude that many of the most common lemmas are just stopwords and need to be removed because they are irrelevant and provide no context to the transcript:
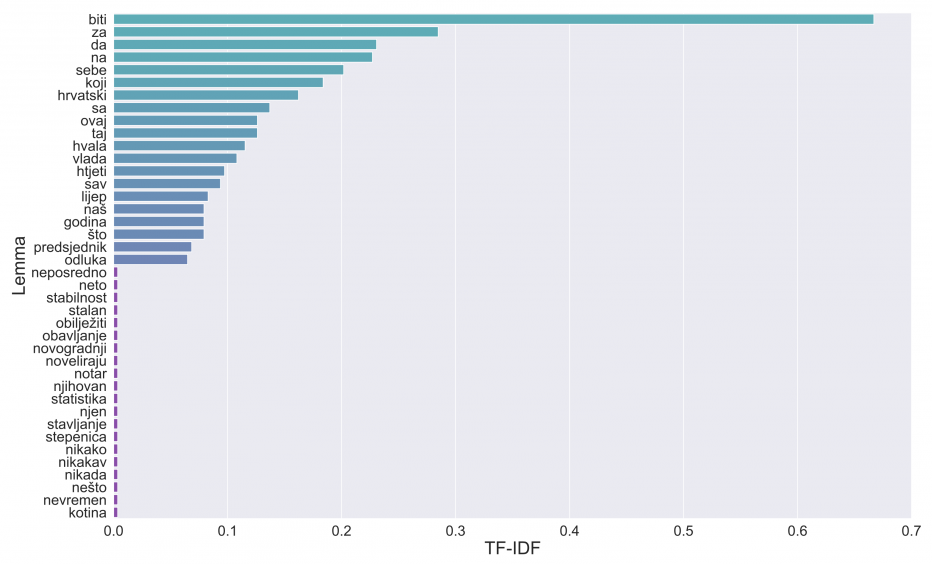
Figure 5 - Lemma frequency
The Python package we used for word cloud generation doesn’t have good support for stopword removal in Croatian. We used Spacy’s stopword list definition for the Croatian language which was also made by CLASSLA.
In Figure 6 we can see a better representation of the most common lemmas in the transcript. Also, the term frequency metric has compressed a little which will help with the extraction of meaningful lemmas. Most of the lemmas at the top of the graph are still not meaningful enough and they can be easily categorized as domain words – words that are often used in government meetings, sessions, or parliament.
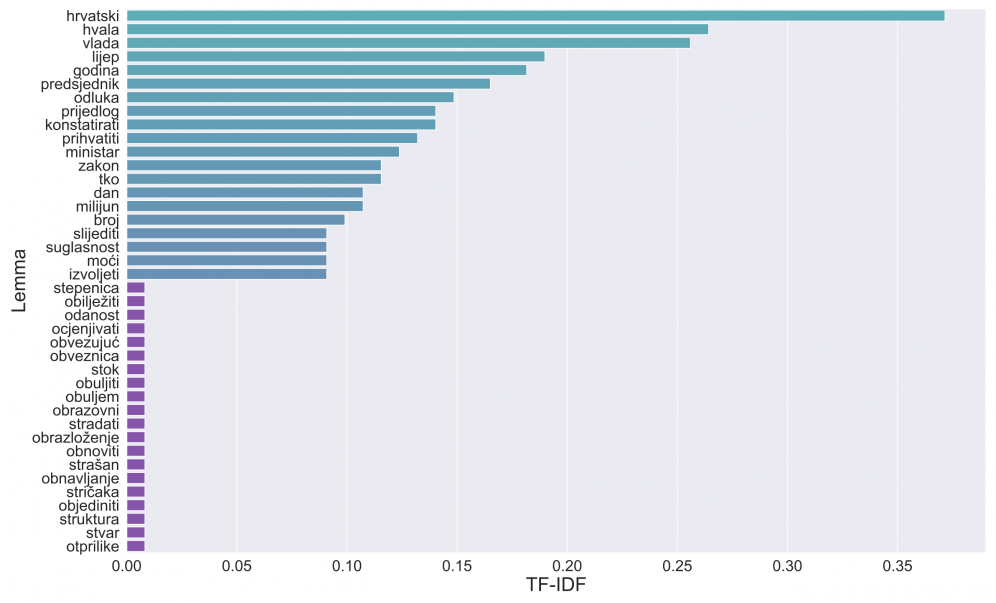
Figure 6 - Lemma frequency after stopword removal
Since there is no easy way of detecting all domain words, we decided to define them as any word with lemma in the top 40 most frequent lemmas. Figure 7 displays visible improvement. Term frequency is even more compressed and unified, and lemmas seem to provide more context on topics discussed in the session:
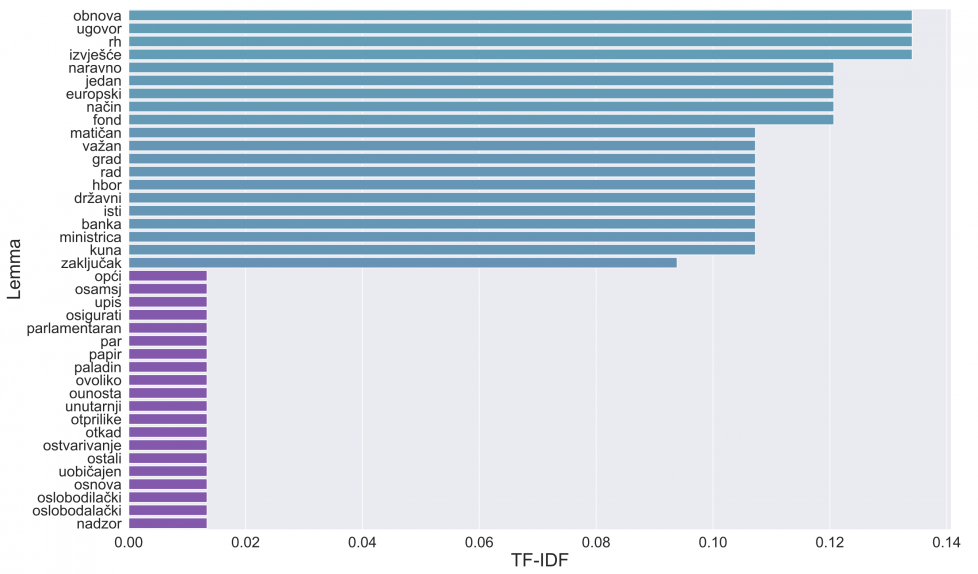
Figure 7 - Lemma frequency after stopword and domain word removal
Finally, we prepared the input for word cloud visualization based on the above conclusions. We tokenized the original transcript and removed all stopwords and domain words.
Below is a generated word cloud for the prepared input. It was created using the WordCloud Python package with 40 as the maximum number of words. Collocations were included because often a word itself isn’t of high importance but the collocation of two words can have significant importance to the context (ex. Words “kolektivni”, “ugovor” and collocation “kolektivni ugovor”).
Numbers were also included because of the high probability of finance topics emerging in the session as well as statistics reporting in any field of government division. We encourage you to take a look at the wordcloud.ipynb notebook on our GitHub page to see word clouds on original input and input with only stopwords removed.

Figure 8 - Word cloud with stopwords and domain words removed
The word cloud now finally paints the picture behind this Gov’t session, so we’ll call it a day here. Up next, let’s see why adding closed captioning may be a good idea.
Closed Captioning for Croatian Gov’t Sessions – Here’s How
Providing closed captions avoids any confusion about what content consumers have listened to. Many times, consumers are not comfortable with a foreign language in the content and could benefit from closed captions in their native language. Finally, closed captions also enable hearing impaired persons be more comfortable with the content, or in severe impairment cases enable them to consume the content at all.
All of these are good reasons why including captions is important on eLearning platforms, at virtual events, or generally any video content meant to be consumed by understanding speech.
Unlike the initial audio processing part described at the beginning, to create captions we split the original audio every 2500 milliseconds and then transcribed all the newly calculated chunks.
To create a .srt subtitle file we followed along with the .srt format and wrote a line number, timestamp, and text output for each.
163
00:06:47.500 –> 00:06:50.000
obnavljanja poljoprivrednih potencijala
In Figure 9 you can see a GIF of a short clip of the original audio played in the VLC player with added generated subtitles file. At the end of the GIF, we can see that the ASR model has some errors in transcribing the speech. This is probably because of vocal imperfections in the speech that should be removed by pre-processing. Another reason is that audio chunks are now 2500 milliseconds long, but the used ASR model performs better when audio chunks are bigger because of the RoBERTa context encoder.
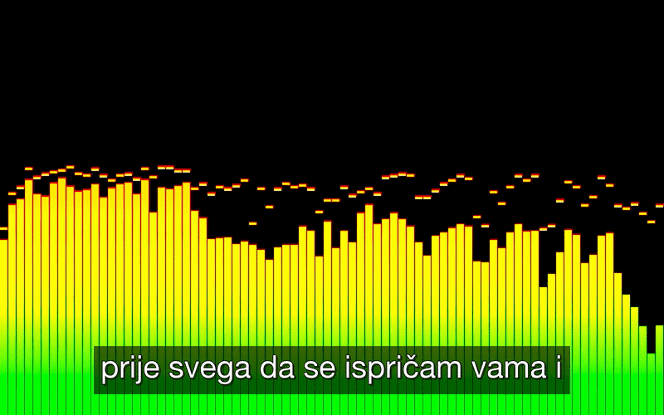
Figure 9 - Demo of the generated .srt file
Summary
Long story short, you can do a lot with an audio file. The most common issue you’re likely to run into is that your language doesn’t have the best support for NLP. That was the case in the Croatian language until recently, but now we have some pretrained model we can work with.
If you have some experience programming in Python and the basic knowledge of deep learning/NLP, then there’s nothing stopping you from implementing speech2text based AI on your data and for your use case. Otherwise, the existing solutions may be too limiting or too expensive – or both.
Do you need help implementing a custom Speech2Text AI solution? Don’t hesitate to reach out to NEOS for help.
Contact
otherTech Blog
01
 02
02
 03
03
 04
04
 05
05

In the news
Small changes, less friction – recent JetBrains updates worth knowing about
26.05.2026
In the news
CLion 2026.2 is focused on the work around the code
29.04.2026
In the news
March updates – proactive AI experiments in JetBrains IDEs, plus Junie CLI in Beta
26.03.2026
In the news
February updates – Java-to-Kotlin conversion in VS Code, plus modern Go output from AI agents
27.02.2026
In the news
January updates – Codex arrives in JetBrains IDEs, plus the CLion 2026.1 roadmap