
get in touch

Gone are the days when R and Python were the only languages for machine learning. There’s a new kid on the block. Sort of. It’s been around since the 1970s, but not in this domain. You’ve guessed it – it’s the language everyone knows – SQL.
Introducing Oracle Machine Learning (OML)
Oracle now offers an entire suite of algorithms for predictive modeling. If you’re coming from a R/Python background, terms like Generalized linear models, k-Means, Naive Bayes, Neural networks, SVD, SVM, and XGBoost should sound familiar. As it turns out, all of them (and many more) come by default with the new Oracle Database 21c.
At Neos, we’ve used OML extensively to build automated time series forecasting pipelines. We’ve extended Oracle’s default functionality to our business needs and developed a package that automatically performs the data preparation, model training, prediction extraction, and database clean up.
You’re not limited to time series, as mentioned a couple of paragraphs ago. The easiest way to get started is by creating a free Oracle Cloud account and provisioning an Always free database instance. Both Autonomous Data Warehouse (ADW) and Autonomous Transaction Processing (ATP) are fine.
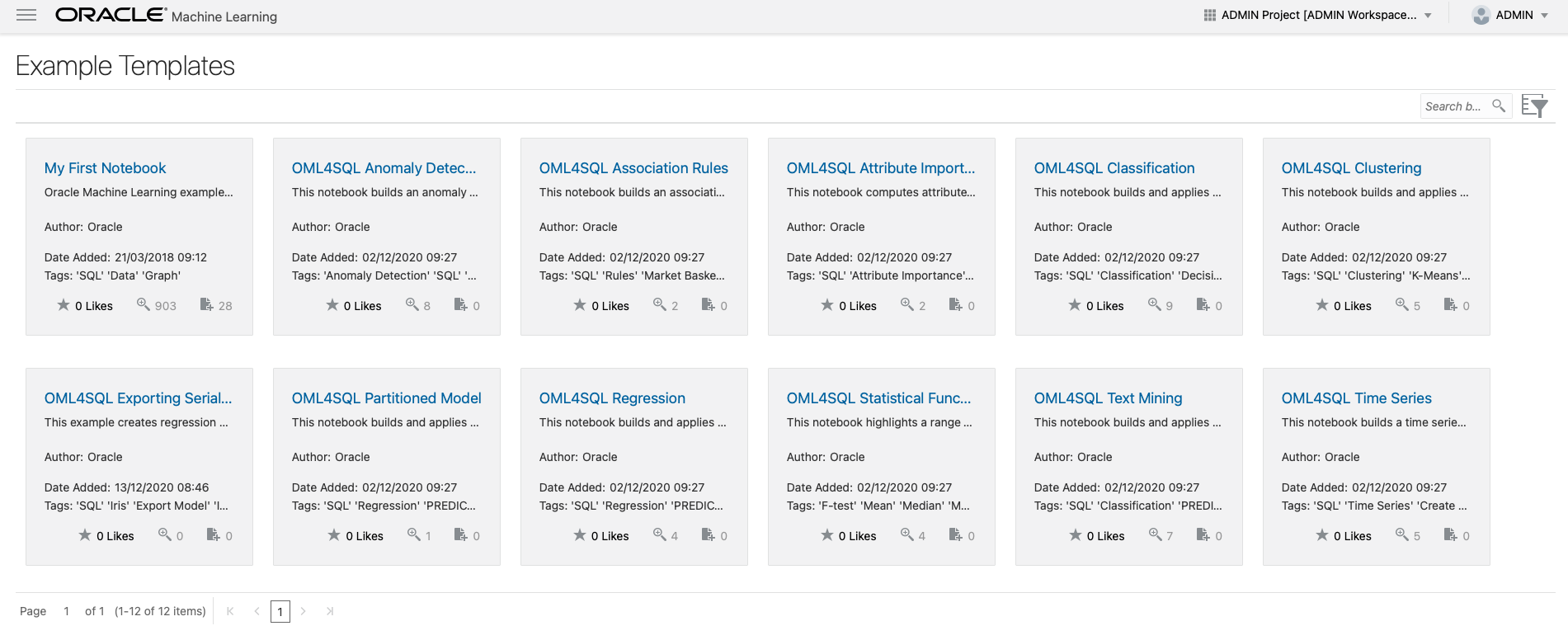
Once the database instance is provisioned, you can open Oracle Machine Learning Notebooks through the Service console. As of now, it comes with a couple of built-in notebooks that are good enough to get you started:
You now have a basic idea of OML and what it’s capable of. The question remains – should you use it?
This question can be answered with two words – it depends. Let’s back this answer up with a couple of pros and cons, so the final decision making is as easy as it can be.
For starters, OML should feel familiar to anyone with decent SQL knowledge. If you’re spending most of your day writing SQL, it makes sense to use OML. Languages like R and Python might seem tempting at first, but it adds an overhead of learning a new language and stepping out of your comfort zone. Not necessarily bad, but why do it if not mandatory?
The second significant advantage is attacking data where it lives. Data is stored in the database, and machine learning is now a part of the same database. There’s no need to drag data to memory for machine learning and then drag predictions back to the database.
As you would expect, things aren’t always unicorns and rainbows, and OML is no exception.
After some playing around with classification and regression algorithms, we’ve noticed that the model performance is worse than those built with R or Python. For example, on the Iris dataset classification, we’ve seen around 90% test set accuracy with OML (Decision trees), while the identical setup in Python yielded 97% accuracy.
Next, there’s a problem with documentation. Documentation exists, but there’s a severe difference between terms documentation and useful documentation. OML falls into the first category. The documentation is so extensive you could read it for weeks, but don’t expect to see any hands-on examples. Guess that’s where paid training and seminars come into play.
Take these considerations into account – maybe they won’t be a downside to you.
Before comparing performance on actual datasets, let’s take a closer look at OML’s direct opponent – Python.
OML Alternative – Machine Learning with Python
More or less, Python is a de facto standard language for data science and machine learning. Communication with the OS, database, and external APIs is something every machine learning project needs, and Python handles it with as few code lines as possible.
After all, Python was designed for teaching programming concepts to kids, so how difficult can it be for tech professionals? (Spoiler alert: not difficult at all).
In a nutshell – if OML can do it, so can Python. Python’s biggest advantage is that it’s not limited to a single approach, and the packages are well-documented. Also, it gives you more options, especially with machine learning – more on that in a bit.
No compilation, no type checks, and interpretable nature of Python can be both a pro and a con. Writing prototypes is as easy as possible, but it’s not the fastest language – especially when not written properly.
At Neos, we’ve used Python to tackle the same problem of automating time series pipelines. But Python allowed us to do more. One of these “added benefit” areas is Explainable machine learning.
With only a couple of lines of code, we ended up with on-demand automatic report generation for machine learning model explanations. For non-data science experts, it’s essential to understand what’s going on below the surface. This way, business users and domain experts can spot unexpected behaviors and enable data scientists to build more robust models.
As with OML, things aren’t always peachy. Developing machine learning models with Python means you have to deploy them somehow. It shouldn’t be an issue, as libraries like Flask and FastAPI make it effortless. Just talk to your nearest DevOps expert – they’ll know what to do.
The other downside of using Python is its Global interpreter lock (GIL). Put simply, it prevents multiple threads from executing Python bytecode at once. There are ways around it, such as using a non-default Python interpreted (e.g., Jython instead of CPython), but more often than not, it brings an entire stack of new problems and considerations with it.
You now know how both OML and Python can be used for predictive modeling. The next section compares the two on actual (but censured) datasets.
Time Series Forecasting – Python or SQL?
At Neos, the most recent project benefiting from machine learning is CloudVane. It collects a lot of time series data and hence requires a lot of time series forecasts. The biggest problem is uncertainty (not the Heisenberg’s one) – a need to train on potentially tens of thousands of time series datasets without prior look and analysis.
You see, time series are different than your regular regression or classification tasks. There’s no point in training a model once and leaving it deployed for months until a substantial amount of new data is acquired. The most important factor for forecasting the next time step is the previous value – so the models need to be updated daily (or even hourly).
Put simply – time series models require retraining every day or every hour to capture the most recent data.
Three things were crucial:
- Automation – because no one wants to do this manually (not sure if even possible)
- Speed – predictions are updated daily or hourly, so the platform needs to train potentially thousands of time series models in a short time frame
- Accuracy – get the best accuracy possible while keeping training speed in mind
Knowing these three considerations limited the scope of what we can do:
- Use the most basic algorithms only if mandatory – e.g., an insufficient amount of training data for anything more sophisticated
- Avoid SOTA algorithms – e.g., avoid RNNs and LSTMs. They are good but don’t train fast enough
And that’s where OML seemed like a way to go. Oracle’s marketing department did its job by presenting 12 algorithms for tackling time series problems. Little did we know at that time, but these 12 algorithms were essentially just a single algorithm – Exponential Smoothing – with many different hyperparameter combinations (trend, seasonality, damped).
Still, we went with it and developed a package that handles time series datasets with ease. Development wasn’t that difficult, but the results weren’t what we expected. Most of the time, the algorithms worked as expected, but they were sometimes way off and behaving unexpectedly. You’ll see a couple of examples in a bit.
On the other hand, Python allowed us to use anything from the basic exponential smoothing algorithms to supervised learning techniques. We ended up combining both (and some different algorithms), depending on the source dataset length and structure.
In a nutshell, combining exponential smoothing with extreme gradient boosting (XGBoost) did the job.
Let’s take a look at a couple of examples.
The first one shows historical data (green) and forecasts generated by OML (red) and Python (yellow). As you can see, the predictions look just the way you would expect:
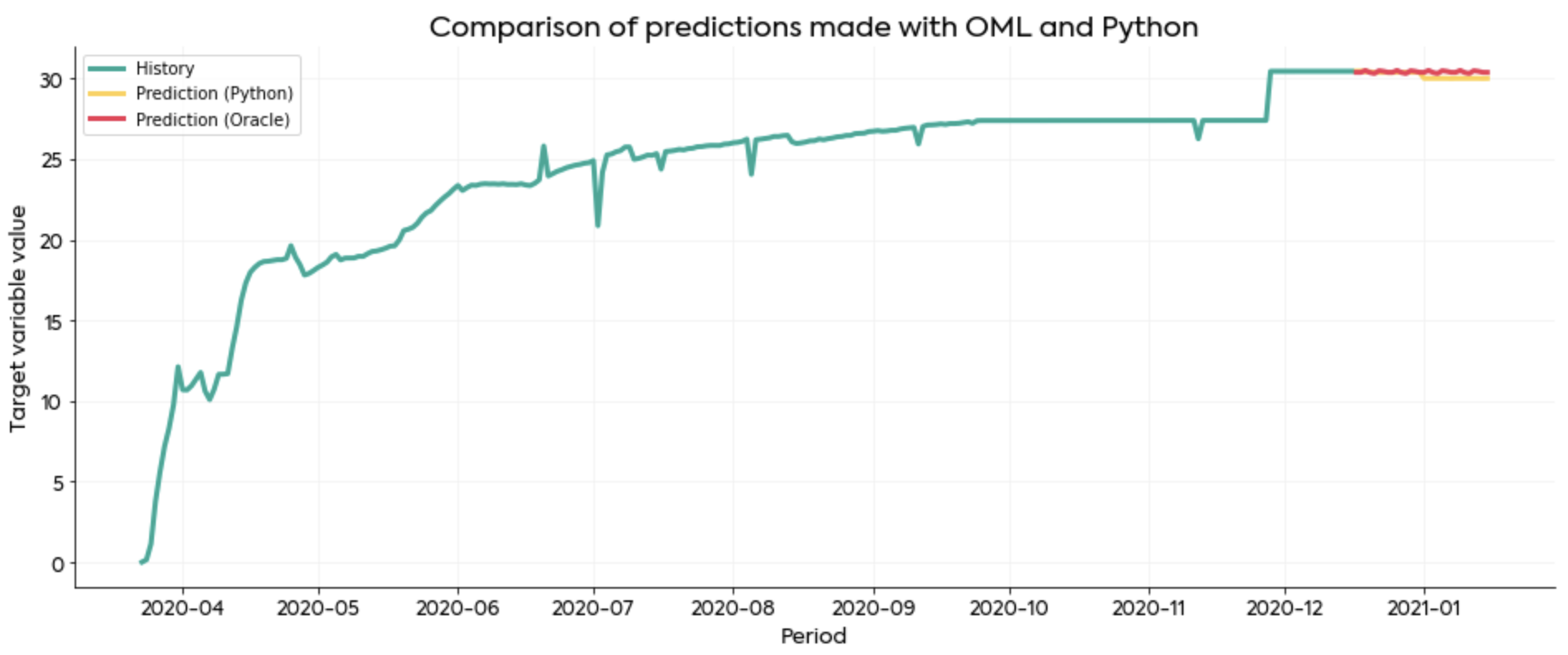
Both approaches are “good enough” to present to the user and for production use in general.
The second example demonstrates a case where OML failed completely for no apparent reason:
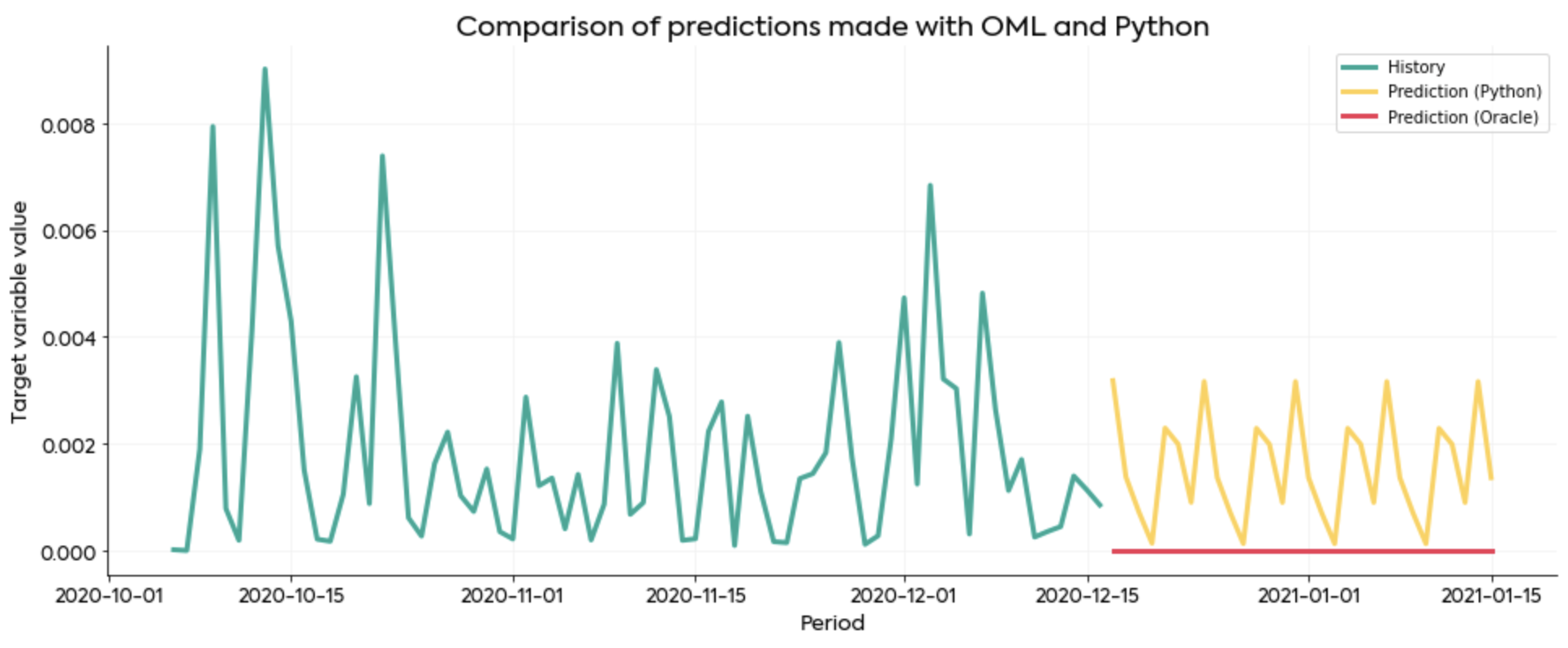
It’s not a whole lot of historical data to train on, but OML should still be able to return something more decent than a straight line located at zero.
There were more generally unexplainable examples, of course, but these two give you an idea of observed behaviors.
Conclusion
To summarize – both OML and Python can be used to make forecasts on time series data. Most of the time, both work as expected, but we’ve noticed unexplainable behaviors with OML.
If machine learning in the database is your only choice, don’t hesitate to go with OML. Just make sure you can perform a model evaluation with ease and keep track of what OML models return. It’s just a matter of time before Oracle fixes these issues.
The safest option as of yet is to keep most of your machine learning logic in Python or R and slowly migrate to the database if needed.
otherTech Blog
01
 02
02
 03
03
 04
04
 05
05

In the news
Small changes, less friction – recent JetBrains updates worth knowing about
26.05.2026
In the news
CLion 2026.2 is focused on the work around the code
29.04.2026
In the news
March updates – proactive AI experiments in JetBrains IDEs, plus Junie CLI in Beta
26.03.2026
In the news
February updates – Java-to-Kotlin conversion in VS Code, plus modern Go output from AI agents
27.02.2026
In the news
January updates – Codex arrives in JetBrains IDEs, plus the CLion 2026.1 roadmap